Ini sekedar catatan dan tips saya saat ini untuk memakai coding agent. Perkembangan coding agent ini sangat cepat, jadi apa yang saya tulis sekarang mungkin tidak akan berlaku lagi di masa depan. Saya ingin menuliskan ini karena siapa tau berguna untuk orang lain, dan juga nanti bisa saya lihat lagi di masa depan seperti apa situasi coding agent di pertengahan 2026.
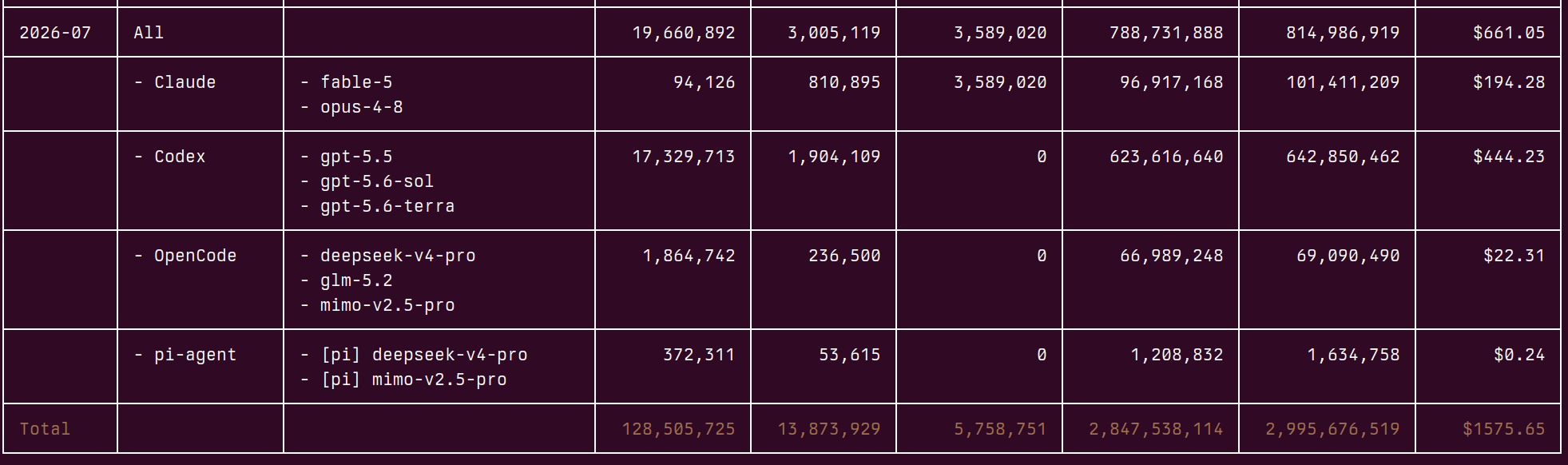
Pemakaian LLM sampai tengah bulan ini, dan total dari awal tahun. Ini cuma di salah satu komputer yang saya pakai
Sejak tulisan terakhir saya, saya merassa:
Agent makin pintar mandiri
Semakin penting untuk memahami harness/coding agent supaya hasilnya optimal
Setelah menulis tentang AI Coding assitant dan Vibe Coding, saya ingin membahas bagaimana cara kerja tool coding ini dan AI Agent secara umum. Secara sederhana: agent ini cuma pemanggilan API chat completion, plus tool use dalam sebuah loop.
Supaya lebih jelas, saya akan menunjukkan langsung bagaimana membuat tool agent yang bisa membantu aneka hal (199 baris Python, kodenya bisa dilihat di https://gist.github.com/yohanes/2af7c4d9dac7ddf0854450da814ecbc5). Tentunya tool ini masih perlu dikembangkan jika ingin masuk production, tapi idenya tetap sama.
Sebagai catatan: saya menggunakan tool uv agar bisa menjalankan Python plus requirementnya dengan PEP 723 tanpa harus menginstall tiap package dengan pip install dulu.
Semuanya sudah saya coba
Saya juga akan membahas aneka fitur yang sekarang dimiliki oleh berbagai agent yang “serius”: AGENTS.md, subagen, MCP, ACP, dan Skill.
Sejak posting terakhir tahun lalu, saya semakin banyak melakukan vibe coding (coding menggunakan bahasa natural, dibantu AI). Saya sudah mencoba banyak tool, dan sekarang sudah mulai nyaman dengan konfigurasi yang ada saat ini.
Claude Code di Termux
Jika kita berusaha memakai semua tool baru yang muncul, maka tidak akan ada habisnya, dan apapun tool yang kita pilih, sebagian orang akan mempertanyakan: kenapa nggak pake tool lain?. Tulisan di blog ini sekedar jadi catatan saat ini, jadi ketika melihat balik, saya bisa tahu apa tool yang saya pakai, dan bagaimana setup saya waktu itu.
Saya sudah memakai editor AI dari sejak beberapa tahun lalu (seperti yang sudah saya tuliskan di sini di tahun 2022). Awalnya hanya sekedar membantu melengkapi kode berikutnya dengan TAB completion, lalu berikutnya saya mulai memprogram dengan memberikan langkah spesifik menggunakan komentar di tengah-tengah fungsi (misalnya: use linear search to find matching elements).
Sekarang saya sudah mulai menggunakan AI Agents, walau cara lama kadang tetap dipakai karena masih berguna untuk algoritma kompleks. Dengan mode agent, kita bisa mendeskripsikan apa yang kita inginkan, misalnya: “buat halaman advanced tutorial, dengan layout yang sama dengan basic tutorial, tapi hanya bisa diakses member premium”, dan AI akan merencanakan semua langkahnya, lalu melakukan apa yang kita minta.
Ketika saya mencoba mode agent ini beberapa bulan lalu, kualitasnya masih agak random, kadang bagus, kadang sangat ngaco. Tapi berbagai model LLM baru sudah muncul yang memang ditraining dengan kemampuan agentic, dan sekarang hasilnya sangat bagus.
Dengan menggunakan Coding Agent (selanjutnya saya sebut agent saja), saat ini ada trend vibe coding, di mana kita memprogram dengan sekedar bahasa inggris dan mengikuti flow saja, tanpa harus melihat kode dengan detail. Sekedar contoh game yang saya vibe code: http://assembly-blocks.pages.dev/ Saya tidak menulis sebaris kode pun. Bahkan saya belum melihat implementasi dalamnya seperti apa, yang penting jalan (karena ini bukan program penting).
Artikel ini bermaksud menjelaskan perbedaan berbagai jenis compiler C, library C, dan juga bagaimana kita bisa memakai SDK (software development kit) untuk suatu platform dengan Compiler C alternatif.
Compiler C
Tugas compiler C adalah menerjemahkan kode dalam bahasa C ke assembly. Kebanyakan compiler bisa membuat file teks .s (source code assembly) yang kemudian bisa dicompile dengan assembler menjadi binary. Sebagian compiler langsung menghasilkan kode biner tanpa melalui assembler.
Compiler hanya menerjemahkan dari C ke assembly
Ketika memprogram microcontroller atau sistem lain yang tidak memakai sistem operasi, kita cuma perlu mengubah alamat memori tertentu untuk melakukan input/output (jika CPUnya mendukung memory-mapped I/O), atau menggunakan instruksi I/O khusus. Sistem semacam ini sebut dengan sistem “freestanding“. Di sistem semacam ini bahkan tidak wajib ada fungsi bernama “main”, programmer yang mendefinisikan fungsi mana yang harus dimulai. Di sistem freestanding, kita bisa membuat program TANPA library C sama sekali.
Sejak ChatGPT dirilis, sudah ada banyak kekhawatiran: sepertinya pekerjaan coding akan digantikan AI. Sekarang sudah sekitar 2 tahun sejak ChatGPT dirilis dan di awal tahun ini ada demo “First AI software Engineer” yang membuat orang terkagum-kagum, tapi ternyata demonya tidak benar dan sampai sekarang perkembangan AI sebagai software engineer belum sesuai ekspektasi yang ada di video demo tersebut.
Orang ini membuat banyak software engineer panik, tapi kemudian hilang kabarnya (sebagai catatan: ini joke, devin masih ada, walau sampai saat ini tidak sebagus hypenya)
Sebagian orang berpendapat bahwa LLM sekarang ini akan mentok sampai level tertentu, dan sebagian lagi berpendapat bahwa LLM masih akan terus berkembang dan akan segera menggantikan software engineer, dan bahkan akan sampai level AGI (Artificial General Intelligence) yang akan bisa menyelesaikan segala macam masalah di bidang apapun.
Retrieval Augmented Generation (RAG) adalah salah satu cara untuk membuat sebuah Large Language Model (LLM) agar bisa menjawab dengan akurat berbasis fakta. Ada banyak variasi detail implementasi RAG, tapi intinya sederhana: kita memberikan informasi berupa teks tambahan kepada LLM untuk menjawab sebuah pertanyaan.
Sebagai catatan: sudah ada banyak sekali produk RAG baik open source maupun komersial. Tulisan ini hanya sekedar memperkenalkan cara kerjanya, supaya tahu bagaimana mengevaluasi produk yang ada atau memodifikasi produknya.
Mari kita bahas beberapa konsep mengenai LLM, embedding, database vektor, dan bagaimana bisa menyusun ini untuk RAG.
Di teks ini saya akan memakai OpenAI API karena saat ini merupakan yang paling mudah dipakai, reliable dan murah. Tapi kita bisa memanfaatkan LLM apapun juga. untuk RAG ini, walau hasilnya bisa bervariasi.
Instruksi SIMD (Single Instruction Multiple Data) adalah jenis instruksi pada prosesor modern yang bisa melakukan operasi terhadap banyak data sekaligus (biasanya bentuknya adalah array/vector). Instruksi assembly dalam sebuah ISA biasanya hanya melakukan hal dasar berikut:
Menyalin data dari memori/register ke memori/register
Melakukan operasi terhadap satu atau lebih register dan menyimpan hasilnya di memori atau register (contoh: penjumlahan, perkalian, operasi bit, dsb). Beberapa operasi akan mempengaruhi flag pada CPU.
Memindahkan alur eksekusi ke alamat tertentu dalam kondisi tertentu (biasanya berdasarkan flag)
Instruksi SIMD bisa melakukan load/save register dari/ke memori, melakukan manipulasi pada register, tapi satu instruksi bisa memproses banyak data sekaligus. Jika dilakukan dengan benar, ini bisa mempercepat program cukup signifikan. Instruksi SIMD tidak bisa melakukan branching ke banyak alamat sekaligus.
Sejarah SIMD ini cukup panjang: singkatnya tahun 1970an sudah dipikirkan ide ini dan sudah diimplementasikan di berbagai komputer besar, tapi baru masuk ke CPU untuk consumer di akhir abad lalu. Data yang diproses semuanya perlu berurutan (seperti array) dan biasanya disebut sebagai vector (tidak berhubungan dengan istilah vektor di matematika).
Zstandard, atau lebih dikenal dengan nama implementasinya: zstd, adalah algoritma kompresi lossless yang sangat cepat dan fleksibel. Algoritma kompresi ini sudah disupport di banyak software, sampai sudah masuk di kernel Linux. Salah satu keunikan kompresi dengan zstandard adalah adanya fitur custom dictionary dan waktu kompresi dan dekompresi yang cepat. Kita bisa membuat custom dictionary untuk aplikasi kita sendiri. Bagian dictionary ini yang akan saya bahas lebih dalam pemanfaatnya di tulisan ini.
Saat ini OpenAI sudah meluncurkan API ChatGPT resmi. Di tulisan ini saya akan memandu bagaimana membuat ChatBot telegram dengan API ChatGPT, dan bagaimana menghosting ini di AWS Lambda. Dengan AWS Lamba, kita bisa menghosting bot telegram secara gratis (sampai setidaknya ratusan ribu pesan per bulan).
Untuk apa menghosting bot sendiri? bukankah sudah ada banyak yang menyediakan gratis di telegram dan WhatsApp? Apakah Anda pernah bertanya: siapa pemilik botnya? apa kebijakan privasi datanya? apakah chat Anda akan direkam selamanya? Sementara versi ChatGPT gratis sekarang sering down ketika dibutuhkan (atau error di tengah percakapan).
Saat ini OpenAI sudah menyatakan bahwa API ChatGPT tidak akan menggunakan data yang kita kirimkan untuk melatih sistem mereka, dan data akan dihapus dalam sebulan. Saya percaya OpenAI bukan karena mereka pasti bisa dipercaya, tapi karena jika mereka tidak patuh, bisa kena denda yang sangat besar. Dengan mengakses API ChatGPT langsung, saya yakin yang memegang data hanya saya dan OpenAI, bukan pihak lain.
Selain itu kita bisa meng-customize bot kita dengan kepribadian sesuai yang kita mau. Bahkan kita bisa membuat banyak bot dengan kepribadian masing-masing. Kita juga bisa menghubungkan output ChatGPT dengan program kita untuk melakukan aksi tertentu.
Contoh bot telegram
Sebelum API resmi diluncurkan, sudah ada yang berusaha membuat API ChatGPT dengan emulasi browser, tapi cara ini kurang stabil dan ChatGPT gratisan sering tidak tersedia (tidak reliable) dan kadang library perlu diupdate tiap kali ada perubahan di sisi OpenAI. Dengan API resmi, kita bisa mendapatkan jawaban dengan cepat dan API-nya tidak akan tiba-tiba berubah tanpa peringatan.
Harga API ChatGPT sangat murah, hanya 0.002 USD per 1000 token. Apa itu token? token adalah pembagian kata yang dilakukan untuk pemrosesan bahasa alami, untuk memahami token, mudahnya bisa langsung mencoba di URL ini. Untuk pemakaian pribadi, ratusan sampai ribuan pertanyaan bisa ditanyakan dengan biaya total puluhan ribu rupiah saja.